Wie zufällig sind Zufallszahlen in der IT?
Dieser Fachartikel widmet sich der Generierung von Zufallswerten mittels Computern. Es wird die Frage behandelt, ob mittels Computern überhaupt echte Zufälle programmiert werden können. Zudem werden unterschiedliche Algorithmen und der Stärken und Schwächen erläutert.
Bedeutung der Zufallszahlen in der IT
Zufallszahlen nehmen in der Informatik eine entscheidende Bedeutung ein. Es gibt diverse Anwendungsgebiete, bei der die Generierung von Zufallszahlen erforderlich ist. Ein einfaches Beispiel wäre die Programmierung eines Würfelspiels, bei dem zufällige Würfelergebnisse erzeugt werden müssen, oder ein Zufallszahlengenerator für eine Auslosung. Zufallszahlen finden zudem bei meteoroligischen und ökonomischen Simulationen Anwendung. Diese Simulationen sind in der Regel extrem komplex. Es gibt diverse unbekannte Variablen, die mangels Rechenleistung selbst auf Hochleistungscomputern nicht berechnet werden können. Für diese unbekannten Größen werden in den Simulationen Zufallszahlen gesetzt.
„Zufälle“ spielen insbesondere in der IT-Sicherheit eine Rolle, beispielsweise beim Erzeugen sicherer Passwörter (Passwortgeneratoren) oder bei der Krytographie. Eine Verschlüsselung ist nur dann sicher, wenn der Schlüssel nicht erraten werden kann. Erfolgt die Schlüsselgenerierung nicht zufällig, sondern sind Muster erkennbar, sind dies für Hacker Angriffspunkte, die das gesamte Verschlüsselungsverfahren angreifbar machen.
Doch wie werden Zufallszahlen durch Computer zeugt? Sind diese wirklich immer zufällig, oder lassen sich diese determinitisch vorhersagen?
Was macht einen guten Zufallsgenerator aus?
Die erzeugten Werte eines Zufallsgenerators sollten nicht vorhersagbar sein, wie schon im vorherigen Abschnitt in Bezug auf Verschlüssungsverfahren erläutert wurde. Zudem sollte jeder Wert aus dem möglichen Wertebereich die gleiche Wahrscheinlichkeit haben, gezogen zu werden. Beispiel: Für Wahlumfragen soll ein Computer zufällig Personen aus Wahlkreisen auswählen. Es gibt 342 Wahlkreise. Dann sollte jeder Wahlkreis bei jeder Ziehung die Wahrscheinlichkeit von 1:342 haben gezogen zu werden. Hat ein Wahlkreis hingegen die Wahrscheinlichkeit 2:342 gezogen zu werden, so kann dies die Genauigkeit der Wahlprognose erheblich negativ beeinflussen.
Kann man Zufall programmieren?
Die Programmierung von wirklichen Zufallswerten ist tatsächlich komplex. Es gibt keine einfache Anweisung, um den Computer mitzuteilen, eine Zufallszahl zu generieren. Computer sind von ihrer grundlegenden Natur und Funktionsweise nicht dafür gemacht, zufällige Ergebnisse zu generieren. Sie folgen unflexibel Programmen und Handlungsanweisungen. Dennoch gibt es in Computerprogrammen scheinbar zufällige Werte und Ereignisse. Um das simple Beispiel aus dem ersten Abschnitt aufzugreifen: Ein Würfelspiel als Computerspiel erzeugt jedes Mal unterschiedliche Würfelergebnisse. Doch wie viel wirklicher Zufall steckt hinter computergenerierten Zufallszahl?
Zunächst einmal wird in der Informatik und Mathematik zwischen zwei Arten von Zufallszahlen unterschieden: Die echten Zufallszahlen und die Pseudozufallszahlen. Pseudozufallszahlen wirken für den Betrachter zunächst einmal wie zufällig ausgewählte Zahlen. Tatsächlich werden Pseudozufallszahlen aber über einen deterministischen Algorithmus erzeugt. „Deterministisch“ bedeutet, dass die Ergebnisse vorhersagbar sind. Solche Algorithmen liefern immer die identische Zufallszahlenfolge, wenn der Algorithmus mit dem selben Startwert (auch als Keim oder Saat bezeichnet) gestartet wird. Für die viele Anwendungsfälle sind Pseudozufallszahlen vollkommen ausreichend, beispielsweise bei Computerspielen. Doch dort wo Genauigkeit und Sicherheit eine entscheidende Rolle spielen, reichen solche einfachen Algorithmen nicht aus.
Um eine echte Zufallszahl zu generieren ist eine „Unsicherheit“, etwas nicht vorhersagbares erforderlich. Man spricht in diesem Zusammenhang auch von einer Entropie. Möglich ist dies zum Beispiel durch die Messung eines nicht vorhersagbaren physikalischen Phänomens, das außerhalb des Computersystem auftritt, in den Zufallsalgorithmus einfließen zu lassen. Man spricht hier von einem physikalischen Zufallsgenerator. Ein Beispiel hierfür ist die Messung des radioaktiven Zerfalls eines Atoms sein. Nach der Quantentheorie ist es nicht möglich, genau zu wissen, wann und wie dieser radioaktive Zerfall voranschreiten wird. Auf die echten Zufallszahlen wird im weiteren Verlauf noch eingegangen. Zunächst sollen die Pseudozufallszahlen näher beleuchtet werden.
Pseudozufallszahlen
Im vorangegangen Abschnitt wurde bereits erläutert, dass es sich bei Pseudozufallszahlen, um Zahlen handelt, die nur den Anschein der Zufälligkeit erwecken, tatsächlich aber vorhersagbar sind. Die meisten Zufallsgeneratoren sind Pseudozufallsgeneratoren, da sich Pseudozufallswerte deutlich schneller berechnen lassen. Im Folgendem wird ein einfacher Algorithmus dargestellt, mit dem sich ein Zufallsgenerator programmieren lässt. Hierzu betrachten wir zunächst die folgenden beiden Zahlenreihen:
- 26, 58, 22, 50, 6, 18, 42, 90, 86, 78
- 88, 83, 73, 53, 13, 32, 70, 47, 1, 8
Für den Betrachter wirken die Zahlen rein zufällig erzeugt. Ein Muster ist ohne Weiteres weder innerhalb noch zwischen den Zahlenreihen erkennbar. Die Zahlen wurden mit einem einfachen Zufallsgenerator generiert, der auf einem simplen Algorithmus basiert: dem linearen Kongruenzgenerator. Dieser wurde 1949 von Derrick Henry Lehmer entwickelt. Der Algorithmus lautet wie folgt:
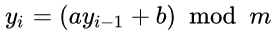
- y ist der Startwert.
- a ist ein Faktor mit der Startwert multipliziert wird.
- b ist das Inkrement, das zum Startwert addiert wird.
- m ist das Modul. Dieser Wert legt die maximale Begrenzung der Zufallszahl fest.
Nach diesem Verfahren werden in der Programmiersprache C/C++ die Zufallswerte der Funktion rand() aus der stdlib.h Bibliothek erzeugt.
Die obigen Zahlenreihen wurden mit folgenden Werten generiert: a = 2, b = 6 und m = 99. Als Startwert wurde für die erste Zahlenreihe 164366730516 gewählt. Für die zweite Zahlenreihe 164366736741.
Beispiel Code-Umsetzung:
Im Folgendem Beispiel ist der Algorithmus in PHP umgesetzt wurden.

Bei mehrfacher Ausführung des obigen Programms wird man feststellen, dass immer die identischen Zahlenreihen ausgegeben werden. Dies ist insofern nicht überraschend, da Pseudozufallsgeneratoren bei gleichem Startwert immer die identischen Werte generieren. Dies ist der Schwachpunkt bei diesen Verfahren. Im obigen Code ist der Startwert „y“ fest auf 2.000 gesetzt. Um bei mehrfacher Ausführung unterschiedliche Ergebnisse zu erhalten, muss der Startwert variieren. Hierfür bietet sich die Uhrzeit in Sekunden an. Mit der Funktion time() erhält man beispielsweise die Anzahl der Sekunden, die seit 1970 vergangen sind. So lässt sich der Startwert bei jeder Ausführung des Programms variieren. Dies erzeugt komplett unterschiedliche Zufallszahlenreihen. Für den Betrachter scheinen die Zahlen nun wirklich zufällig zu sein. Das Grundproblem bleibt jedoch: Die Zufallszahlen sind vorhersagbar, da diese immer abhängig vom Startwert sind. Über Reverse-Engineering lassen sich, insbesondere bei diesem simplen Algorithmus, schnell die einzelnen Variablen bestimmen. Kennt ein Hacker die Variablen a und b, so kann er für jeden Startwert die Zufallszahlen bestimmen.
Es gibt noch weitere Algorithmen zur Erzeugung von Pseudozufallszahlen, beispielsweise das Mersenne-Twister-Verfahren von Makoto Matsumoto und Takuji Nishimura aus dem Jahre 1997.
Echte Zufallszahlen
Im Abschnitt „Kann man Zufall programmieren?“ wurden bereits die echten Zufallszahlen erläutert. Diese sind nicht vorhersagbar. Möglich ist dies, wenn man auf physikalische Phänomäen misst, die nicht vorhersagbar sind. Hier wurde bereits der radioaktive Zerfall als mögliche Entropie genannt. Weitere zufällige Werte könnten sich aus folgenden Messungen ergeben:
- Atmosphärenrauschen (wie analoges Radio, welches nicht auf einen Sender abgestimmt ist).
- CCD-Sensorrauschen (mit einer schlechten (z. B. alten Mobiltelefon-) Kamera in einem dunklen Raum fotografieren und daraus Zufallszahlen ableiten).
- Spannungsschwankungen an einer Z-Diode.
- Lawinenrauschen an einer pn-Diode.
Auf diese physikalischen Phänomäne soll nicht weiter eingegangen werden, denn solche Verfahren sind in der Regel wenig praxistauglich:
- Diese Verfahren sind langsam und eignen sich nicht für die schnelle Erstellung einer großen Menge an Zufallswerten.
- Stehen solche Messmethoden nur einem sehr begrenzten Personenkreis zur Verfügung.
Annähernd zufällige Verfahren
Die Erzeugung echter Zufallswerte ist also komplex. Es gibt jedoch Möglichkeiten sich dem Zufall anzunähern, in dem man schwer vorhersagbare Ereignisse mit einbezieht, die innerhalb des Computersystem stattfinden. Die kann zum Beispiel die Mausbewegungen des Users sein, die Intervalle zwischen Tastaturanschlägen, die Auslastung der CPU oder eine Prozessüberwachung des Betriebssystems. Diese Werte ließen eine gewisse Entropie in den Algorithmus einfließen. Dennoch eignen sich diese Werte nur bedingt, da sie einem gewissen Muster folgen. Bei der Generierung einer großen Menge an Zufallszahlen können diese Muster sichtbar werden.
Hast Du Fragen oder Anmerkungen zum Artikel? Schreibe einen Kommentar.
Schreibe einen Kommentar